8月13日,國(guó)際學(xué)術(shù)期刊Cell Discovery在線發(fā)表了中國(guó)科學(xué)院上海營(yíng)養(yǎng)與健康研究所計(jì)算生物學(xué)重點(diǎn)實(shí)驗(yàn)室(馬普計(jì)算生物學(xué)研究所)邵振研究組研究論文“MAP: model-based analysis of proteomic data to detect proteins with significant abundance changes”,報(bào)道了一種新計(jì)算模型MAP,用于統(tǒng)計(jì)分析基于同位素標(biāo)記產(chǎn)生的定量蛋白質(zhì)組數(shù)據(jù)并鑒定其中差異表達(dá)的蛋白質(zhì)。
基于同位素標(biāo)記和質(zhì)譜技術(shù)的定量蛋白質(zhì)組實(shí)驗(yàn)(如iTRAQ、TMT和SILAC等)能同時(shí)檢測(cè)數(shù)千甚至上萬(wàn)個(gè)蛋白質(zhì)在不同樣本之間的相對(duì)豐度或表達(dá)差異。這類數(shù)據(jù)已有的差異表達(dá)分析方法大多依賴于對(duì)并行或已有的技術(shù)重復(fù)數(shù)據(jù)進(jìn)行前期比較來(lái)構(gòu)建實(shí)驗(yàn)的技術(shù)誤差模型,并以它為基礎(chǔ)檢驗(yàn)每個(gè)蛋白質(zhì)在被比較樣本之間表達(dá)差異的統(tǒng)計(jì)顯著性。該方法占用了有限的實(shí)驗(yàn)通道,也難以保證誤差模型的精確適用性。
針對(duì)這一局限,在MAP模型中研究人員發(fā)展了一種新穎的分步回歸(step-by-step regression)分析流程,實(shí)現(xiàn)直接對(duì)被比較的兩個(gè)iTRAQ樣本構(gòu)建技術(shù)誤差模型。在此類研究中,一個(gè)常用的經(jīng)驗(yàn)假設(shè)是技術(shù)誤差對(duì)樣本間每個(gè)蛋白質(zhì)iTRAQ信號(hào)log2比率(log2-ratio)的貢獻(xiàn)服從以0為中心的正態(tài)分布N(0, σ2)。其中,方差σ2依賴于該蛋白質(zhì)的信號(hào)強(qiáng)度,并且常被用一個(gè)指數(shù)衰減函數(shù)來(lái)刻畫其依賴關(guān)系,即所要構(gòu)建的全局誤差函數(shù)。MAP模型首先使用滑動(dòng)窗口掃描兩個(gè)樣本的M-A圖,同時(shí)對(duì)窗口中0附近的log2比率進(jìn)行線性建模,以其斜率的平方作為誤差函數(shù)的局域估計(jì)。然后,對(duì)所得局域估計(jì)進(jìn)行第二輪指數(shù)擬合,獲得被比較樣本的全局誤差函數(shù),并以它為參照計(jì)算每個(gè)蛋白質(zhì)信號(hào)差異的顯著性P值(圖一)。
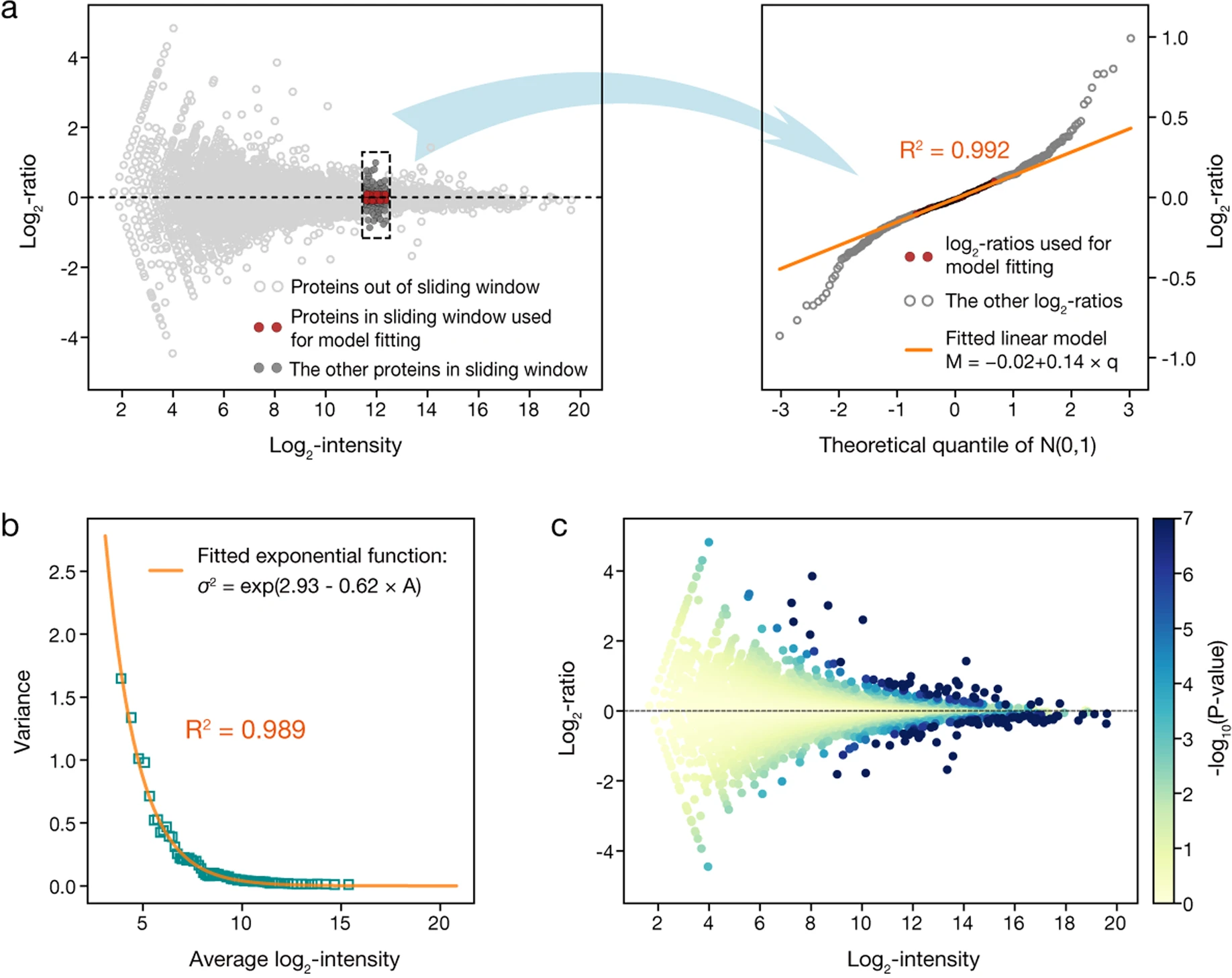
圖一:MAP模型的分步回歸分析流程。
(a)局域線性擬合;(b)全局指數(shù)擬合構(gòu)建技術(shù)誤差模型;(c)計(jì)算每個(gè)蛋白質(zhì)信號(hào)差異的顯著性P值。
同位素標(biāo)記定量蛋白質(zhì)組數(shù)據(jù)長(zhǎng)期存在比率壓縮的難題。研究人員使用MAP模型分別比較分析了三個(gè)批次產(chǎn)生的小鼠胚胎干細(xì)胞分化前后蛋白質(zhì)組數(shù)據(jù),發(fā)現(xiàn)蛋白質(zhì)iTRAQ信號(hào)log2比率在不同批次間關(guān)聯(lián)很低(圖二a),可能是因?yàn)榧夹g(shù)誤差對(duì)其貢獻(xiàn)所服從的正態(tài)分布N(0, σ2)在批次間各不相同。根據(jù)MAP模型,研究人員提出使用每個(gè)批次的全局誤差函數(shù)對(duì)其中每個(gè)蛋白質(zhì)iTRAQ信號(hào)的log2比率進(jìn)行重標(biāo)度(rescaling),使得在不同批次中技術(shù)誤差對(duì)其貢獻(xiàn)均服從標(biāo)準(zhǔn)正態(tài)分布N(0, 1),從而發(fā)展了一個(gè)新的Z統(tǒng)計(jì)量。比較不同批次蛋白質(zhì)Z統(tǒng)計(jì)量之間的關(guān)聯(lián),可以發(fā)現(xiàn)它具有明顯更好的可重復(fù)性(圖二b)。
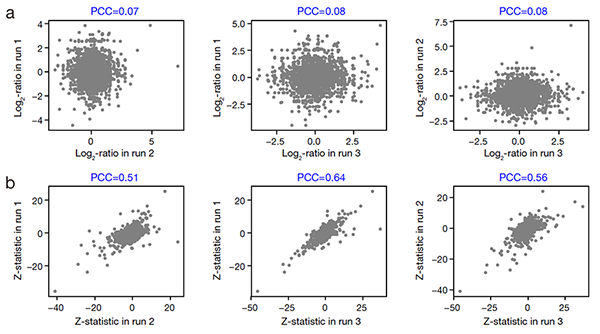
圖二:不同批次蛋白質(zhì)iTRAQ信號(hào)的log2比率(a)和Z統(tǒng)計(jì)量(b)的皮爾森關(guān)聯(lián)系數(shù)。
為方便蛋白質(zhì)組領(lǐng)域研究者使用MAP模型進(jìn)行數(shù)據(jù)分析,研究人員搭建了一個(gè)網(wǎng)絡(luò)服務(wù)平臺(tái)(http://bioinfo.sibs.ac.cn/shaolab/MAP)。該平臺(tái)額外搭載了一個(gè)整合分析模塊,能夠通過(guò)整合多個(gè)批次生物重復(fù)比較結(jié)果的次優(yōu)P值或者平均Z統(tǒng)計(jì)量來(lái)最終鑒定差異表達(dá)蛋白質(zhì),并新發(fā)展了一種分析方法用于估測(cè)基于這些統(tǒng)計(jì)量所定義差異表達(dá)蛋白質(zhì)的錯(cuò)誤發(fā)現(xiàn)率(FDR)。此外,在用于雙樣本比較的MAP模型基礎(chǔ)上,研究人員還通過(guò)分別用樣本方差和卡方分布分位數(shù)取代原分步回歸建模流程中所使用的log2比率和標(biāo)準(zhǔn)正態(tài)分布分位數(shù),進(jìn)一步發(fā)展了適用于多樣本比較的拓展eMAP模型。
上述研究由中國(guó)科學(xué)院上海營(yíng)養(yǎng)與健康所研究助理李木山和博士研究生涂世奇等在邵振研究員的指導(dǎo)下,與中國(guó)科學(xué)院植物生理生態(tài)研究所、復(fù)旦大學(xué)上海醫(yī)學(xué)院和美國(guó)西南醫(yī)學(xué)中心等多家單位的研究人員合作完成,得到了國(guó)家自然科學(xué)基金委、科技部和中國(guó)科學(xué)院等多項(xiàng)基金的資助。
 官方微信
官方微信