2022年1月20日,中國科學院上海營養與健康研究所李海鵬研究組聯合其他團隊,在人類遺傳學領域的國際重要學術期刊Human Genetics在線發表了題為“Fine human genetic map based on UK10K data set”的研究論文。遺傳重組是生命進化的基礎,在有性生物形成配子的過程中,來自父方和母方的染色體相互交換遺傳物質,從而極大地增加了相鄰基因間不同等位基因的組合,豐富了遺傳多樣性。精確度量基因組不同區域的遺傳重組率,始終是生物學研究的一個熱點問題。精確的遺傳重組圖譜對研究遺傳重組的發生機制,雜交育種,準確定位致病突變和某一性狀的決定基因,均是非常重要的。
遺傳重組率估值的精確度,與數據中所囊括的遺傳重組次數成正比,如果數據中囊括了越多的遺傳重組事件,則遺傳重組率估值越精確,反之亦然。這一原則,無論是基于家系或單精子測序的研究,還是基于群體遺傳數據的研究,均是成立的。基于群體遺傳數據的分析,局限于已有的分析方法,很難運用來分析大樣本。在這一研究中,研究者擴展了前期開發的機器學習方法,運用新開發的FastEPRR 2.0分析了公開的UK10K共3,781個非相關個體(n=7,562個基因組)測序數據,基于Out-of-Africa群體歷史模型,準確估計了遺傳重組率,構建了精確的遺傳重組圖譜。總體上看,少數已知的遺傳重組熱點在UK10K遺傳圖譜中依然存在,但在UK10K遺傳圖譜中,遺傳重組率估值波動較為平緩,遺傳重組異質性較低(圖1)。為了探究樣本大小對估值的影響,研究者從UK10K數據中隨機選取了2,000、400和200個基因組測序數據,分析結果顯示,隨著樣本量的降低,遺傳重組率的估值波動加大。上述結論并不依賴于分析時所用的群體歷史模型,研究者在使用群體數量恒定模型中也觀察到了同樣的現象。這一新的研究成果不但為學術界提供了精確的人類遺傳重組圖譜,并且發現遺傳重組在基因組上的分布可能要比目前預期的更加均勻。正如一個評審人所說,目前對遺傳重組的研究,整個學術界傾向于發現越來越多的遺傳重組熱點,但是這篇文章卻指出了另一可能。
理論群體遺傳學領域有著極其完善的數學基礎,與機器學習中的黑盒子概念截然相反。但是研究者在2008年初,已經準確預見到了有監督的機器學習對群體遺傳學的促進作用,因此在2011年與合作者一起首次將有監督的機器學習引入了群體遺傳學(Genetics)、并在2013年(Genetics)、2016年(G3)持續發展這一新范式。雖然有監督的機器學習在某些方面做得比極大似然法、貝葉斯等方法更好,但是這一新范式究竟能否為進化生物學領域帶來新發現,依然是未知的。研究者的研究結果表明,新范式帶來了新發現,同時也正面回應了領域中某些質疑意見。
中國科學院上海營養與健康研究所李海鵬研究員和華東師范大學的潘逸萱副教授為該論文的共同通訊作者。郝子謙博士和杜朋元博士為共同第一作者。該課題得到了國家自然科學基金、中國科學院先導項目、科技部國家重點研發計劃和中科院上海營養與健康研究所的支持。
PubMed鏈接:https://pubmed.ncbi.nlm.nih.gov/35048190
全文下載鏈接:https://rdcu.be/cFkND
UK10K鏈接:https://www.uk10k.org
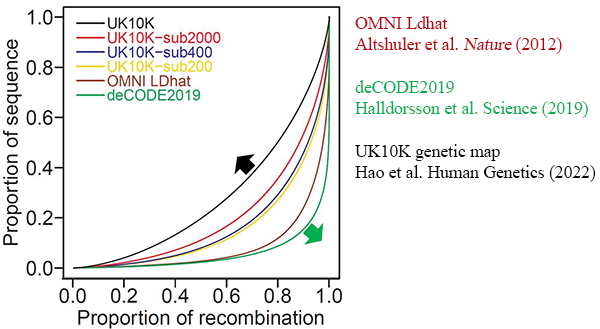
圖1、各個遺傳重組圖譜中遺傳重組異質性的統計。如果遺傳重組在基因組中均勻分布,此時將不存在任何遺傳重組異質性,并且對應曲線為對角線。如果基因組中遺傳重組異質性越高,則有更多的遺傳重組熱點,對應曲線越彎曲。
 官方微信
官方微信